Generation of poems with a recurrent neural network
Overview
In this article, I will present the structure of a neural network (NN) that is capable of generating poems. Neural networks are the technology standing behind deep learning, which is part of the machine learning discipline. The main value of this article is not to present you with the best possible artificially generated poems, or the most advanced state of the art NN architecture for generating poems, but rather presenting a relatively simple structure that performs surprisingly well in a quite complicated natural language processing (NLP) task.
If you are a machine learning (ML) practitioner, understanding the structure of this network could give you ideas on how to use parts of this structure for your own ML task.
If you are willing to start developing NN by yourself, recreating this network by yourself could be a good place to start. This network is simple enough to build from scratch, as well as complicated enough to require the usage and understanding of basic training techniques.
Next, we will see related works, some real predictions that my neural network has made, and then see the network structure.
Figure 1: Poem fragments generated by RNN
The project was presented at the M-AI SUMMIT 2018 in Munich. Watch the video to discover more about it or continue reading the article…
Related work
Andrej Karpathy [1] has a very interesting article about poem generation with RNN. His article provided the background and motivation for this writing. Karpathy´s implementation uses Lua with Torch, I use Python with TensorFlow. For people who are interested in learning TensorFlow, the code behind this article may be a good reference implementation.
Hopkins and Kiela [3] propose more advanced NN architectures that strive to generate poems indistinguishable from human poets. Examples of poems generated by their algorithms can be seen here [4]. Ballas provides an RNN to generate haikus and limericks here [6].
A whole magazine with machine generated content including poems is available here [5]. Online poem generator is available here: [7]. Lakshmanan describes how to use Google Cloud ML for hyper-parameters tuning of a poem generating NN [8].
The poem writing problem definition
As a first step, let’s rephrase the problem of writing a poem to a prediction problem. Given a poem subject, we want to predict what a poet would write about that subject.
Figure 2: Poet writing
As a second step, let us break down the large prediction problem into a set of smaller ones. The smaller problem is to predict only one letter (character) that a poet´s would write following some given text. Later we will see how to predict poet’s writing on a subject using one character predictor.
For example, can you guess what would be the next character here?
Figure 3: Prediction riddle 1

This is an easy riddle to solve for two reasons:
- It appears in the training text when we use Shakespeare for training
- It is the last letter of a sentence. The last letter is easier to guess because there are few grammatically correct variants.
Let’s try another one:
Figure 4: Prediction riddle 2

Here we want to guess the first letter of the new sentence. This is much harder, because many grammatically correct variants are possible, and it is hard to know which variant Shakespeare would choose.
Prediction of the next character
Theory
To predict the next character we need a neural network that can read any number of given characters, remember something about all of them, and then predict the next.
Figure 5: Input

A good candidate for this kind of task is a recurrent neural network (RNN).
A recurrent neural network is a neural network with a loop in it. It reads input one character at a time. After reading each character xt it generates an output ht and a state vector st, see Figure 6. The state vector holds some information about all the characters that were read up until now and is passed to the next invocation of the recurrent network. A great explanation of RNNs is provided by Olah [2].
Figure 6: Recurrent neural network

Figure 7 shows the RNN unrolled in time.
Figure 7: Unrolled RNN

The first input character goes to x₀ , the last goes to xt, the output h₀ is the prediction for the character that a poet would write after x₀, where h₁ is the character that will follow x₁, and so on.
Real examples of RNN outputs
Now let us see some examples of the real predictions that my NN has made. Figure 8 shows the example input, the expected output, which is the input shifted by one character right, and the actual output.
Figure 8: Example RNN output
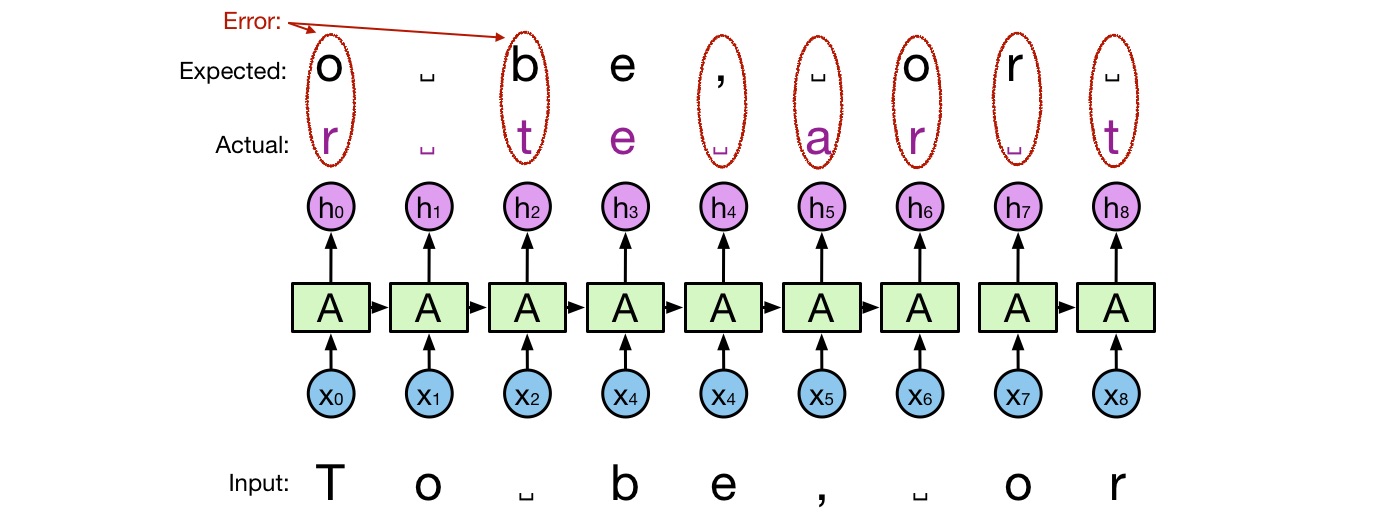
The actual output does not match exactly the expected output. This is natural because otherwise, we would have an ideal network that predicts with perfect accuracy, which is not the case in practice. The difference between the expected and the actual prediction is called error or loss.
During training, the NN is improved step by step to minimize loss. The training process uses training text to feed the network with pairs of input and expected output. Each time the actual output differs from the expected output, the parameters of the NN are corrected a bit. In our case, the training text is the collection of Shakespeare’s works.
Now let us see more examples of the predicted characters, and in particular how the prediction improves as the training goes. Figure 9 shows a sequence of predictions after a different number of training steps.
Figure 9: Outputs at different training stages

Here, the input string is “The meaning of life”. After 4,941 steps, we have 11 incorrectly predicted characters (marked in red). After 34,587 steps, the number of prediction errors fell to 7.
We can see that more errors appear at the beginning of a string than at the end of a string. This is because by the end of the string the network reads more characters and its state contains richer information. This richer information leads to better and more informed predictions.
Generation of the entire poem
At the beginning of this article we focused on a smaller problem of predicting one character of a poem, now we are coming back to the larger problem of generating the entire poem. So having a trained RNN at hand that can predict one character, we can employ the scheme depicted in Figure 10 to generate any number of characters.
Figure 10: Generation of many characters

First, the poem subject is provided as an input at x₀, x₁, x₂, …. Outputs preceding h₀ are ignored. The first character that is predicted to follow the poem subject, h₀, is taken as the input to the next iteration. By taking the last prediction as the input for the next iteration we can generate as many characters as we desire.
We can look at the above scheme from a different perspective, see Figure 11.
Figure 11: Encoder — decoder perspective
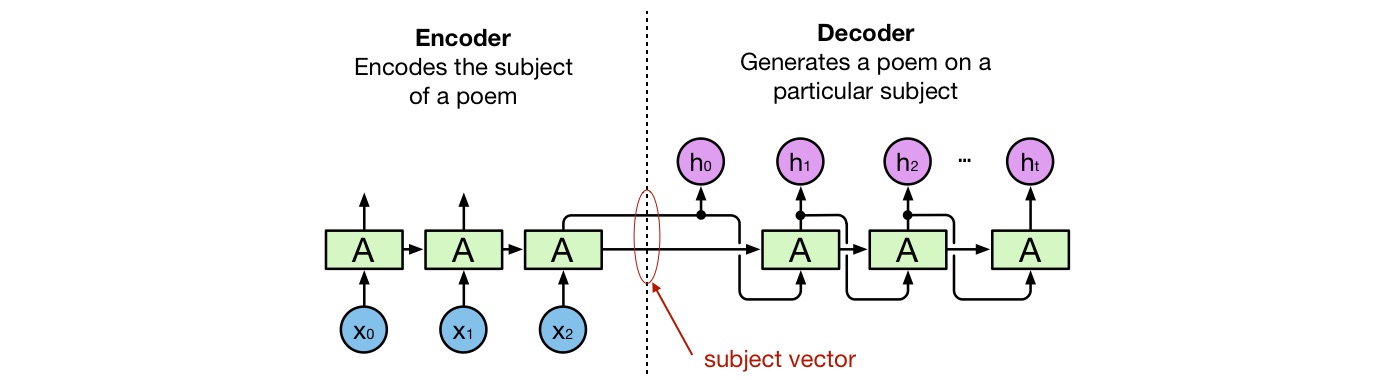
The left part of the network is an encoder that encodes the poem subject in a vector representation, called subject vecotor or theme vector. The right part of the network is a decoder that decodes the subject vector into a poem.
This perspective is used in machine translation systems. There, an encoder encodes a sentence in a source language into a vector representing its meaning. Then, the decoder decodes the meaning vector into a sentence in a target language.
Examples of generated poems
Shakespeare
We will now see a series of examples of generated poems. Those examples were generated at various stages of the training process, and demonstrate how the generated poem improved during the training. The poem subject is: “The meaning of life”. The network is trained on the works of Shakespeare. Here is a small excerpt from the training text, which is the original Shakespeare writing:

Training step: 1 – time: 0 min

This is just the beginning of the training process. All the network parameters are initialised to random values, and still remain at this state. Therefore, the output is just a random collection of characters.
Training step: 140 — time: 5 min

We are 5 minutes in to the training process, at step 140. The network learned the distribution of characters in English text and outputs the most frequent characters, which are: space, e, n, r, and o
Training step: 340 — time: 11 min

Here, additional frequent characters appeared: t, h, s, and i.
Training step: 640 — time: 21 min

Here, the network learned several new things:
- The space characters are now distributed correctly. Word lengths now closely resemble the lengths of words in English text.
- The text is organized in paragraphs of meaningful length.
- Every paragraph begins with a name of a play personage, which is followed by a colon.
- Short and frequent words start to appear, such as: the, so, me
- The network learned the concept of vowels and consonants. They appear in a more or less natural order. For example, a sequence of letters
"touherthor"from the above text, if read, sounds like a valid word. This is due to the correct distribution of vowels and consonants.
Training step: 940 — time: 31 min

Longer words appear, like: would, here, hire
Training step: 1,640 — time: 54 min

Here we start to see correct sequences of correct words: "the fort of the hands", or "the world be the worth of the".
Training step: 6,600 — time: 3h 29 min

Now we see the first signs of a grammatical structure of a sentence. The sequence of letters: "That they are gone" resembles a sentence with a correct grammatical structure.
Training step: 34,600 — time: 19 hours

This is as far as this networks can get. After 19 hours of training process reaches its limit, and the output does not improve any more.
Goethe

This is an output of an RNN trained on Goethe’s Faust. The output is taken after the training process reached its limits.
Pushkin

The same as above but trained on Pushkin.
Conclusion
We have seen a recurrent neural network that can generate poems. We have seen how the network output improves as the training process goes.
This is not the best possible neural network to generate the best poems. There are many ways to improve it, some of them mentioned in related works sections. This is a simple neural network that achieves surprisingly good results.
If you are interested in repeating this exercise by yourself, the code behind this article can be found at: github.com/AvoncourtPartners/poems. The network is implemented in Python using TensorFlow.
References
[1] Andrej Karpathy. “The Unreasonable Effectiveness of Recurrent Neural Networks”
[2] Cristopher Olah. “Understanding LSTM Networks”
[3] Jack Hopkins and Douwe Kiela. “Automatically Generating Rhythmic Verse with Neural Networks.” ACL (2017).
[4] http://neuralpoetry.getforge.io/
[5] CuratedAI — A literary magazine written by machines, for people.
[6] Sam Ballas. “Generating Poetry with PoetRNN”
[7] Marjan Ghazvininejad, Xing Shi, Yejin Choi, and Kevin Knight. http://52.24.230.241/poem/index.html
[8] Lak Lakshmanan. “Cloud poetry: training and hyperparameter tuning custom text models on Cloud ML Engine”